OpenStreetMap User's Diaries
the first 20.000 contributions
I’ve been updating bus routes;
it’s a fun task, but takes a real long time;
slow progress in the wiki: osm.wiki/Braga
i’ve added tons of sidewalks and crosswalks and i’m totally happy to see them start rendering on OSMAnd;
if ppl actually used OSM while driving they would get vocal warnings for crosswalks, i’ve tried it before and it works and its really good to know wheneve
I’ve been updating bus routes;
it’s a fun task, but takes a real long time;
slow progress in the wiki: osm.wiki/Braga
i’ve added tons of sidewalks and crosswalks and i’m totally happy to see them start rendering on OSMAnd;
if ppl actually used OSM while driving they would get vocal warnings for crosswalks, i’ve tried it before and it works and its really good to know whenever you approach a sidewalk as a driver; ofc this is a feature which is pedestrian centered, so the whole point is to especially help people navigate on foot; also i really like the added complexity layer when sidewalks appear on the map and you can actually start navigating the city through sidewalks, footways, footpaths and informal paths, the city is more interesting when seen through a walking perspective
we need to properly address this, i’m thinking of starting activism, we cant have 300 ppl getting run over per year (just in braga!)
i’m quite confused if and how exactly i should mark informal crossings (especially in cases where theres heavy crossing pedestrian and bike traffic (see: node/1888043292); it may seem easy but im afraid that ppl could get misled into crossing in a bad place;
there should be a more compreensive aproach to these situations so we can map this for safety first; then, we should take this stuff to city hall and press for more permanent proper solutions, like new crossroads and better safety measures!!!
as to sidewalks, it’s a bad situation; there are not as many as i believe there should be (this gets really bad as you get farther from the city center).
so many of the newer roads and rotundas dont even have a proper sidewalk, like whaaat;
i do this out of sheer worry bcs i know how hard it is to navigate the city while not knowing which side of the road you should be on to be able to actually get where you wanna go, bcs sidewalks collapse onto the road or suddenly dissappear into nowhere. (“wheres the crosswalk?”) so this feels important specially to point people towards the safest marked crossing and so they can check which sidewalk is in better state etc.
also i really like informal paths, and pedestrian exclusive paths like alleyways or roadside paths… i’ve added some of those to guimaraes already also;
one interesting case i found is this (rare in Braga) alley, which is closed off by a fence way/1463261788; - which is kind of a similar situation to this in guimaraes way/1463370151 ; in both cases they are exclusively pedestrian paths, which do exist, where built up, in the case of guimaraes have even public lighting equipment and stuff but they are closed off to the public (god knows why)= so i added them out of curiosity for osm urban dwellers; i tried to keep them clearly tagged as closed or having no entry or exit, but they do exist so i believe its ok to have them mapped, even if they are not allowed access for some reason
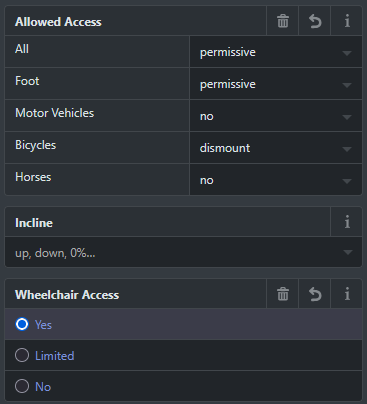
mapping for accessibility is a goal, but a bit complex; i havent mapped curbs to most of my crosswalk interventions yet, bcs sometimes its hard to know whats their state;
a thing i like are wayside shrines, i’m starting to map them, i’ve added 3 or 4 so far;
I’ve been updating bus routes;
it’s a fun task, but takes a real long time;
slow progress in the wiki: osm.wiki/Braga
i’ve added tons of sidewalks and crosswalks and i’m totally happy to see them start rendering on OSMAnd;
if ppl actually used OSM while driving they would get vocal warnings for crosswalks, i’ve tried it before and it works and its really good to know wheneve
I’ve been updating bus routes;
it’s a fun task, but takes a real long time;
slow progress in the wiki: osm.wiki/Braga
i’ve added tons of sidewalks and crosswalks and i’m totally happy to see them start rendering on OSMAnd;
if ppl actually used OSM while driving they would get vocal warnings for crosswalks, i’ve tried it before and it works and its really good to know whenever you approach a sidewalk as a driver; ofc this is a feature which is pedestrian centered, so the whole point is to especially help people navigate on foot; also i really like the added complexity layer when sidewalks appear on the map and you can actually start navigating the city through sidewalks, footways, footpaths and informal paths, the city is more interesting when seen through a walking perspective
we need to properly address this, i’m thinking of starting activism, we cant have 300 ppl getting run over per year (just in braga!)
i’m quite confused if and how exactly i should mark informal crossings (especially in cases where theres heavy crossing pedestrian and bike traffic (see: node/1888043292); it may seem easy but im afraid that ppl could get misled into crossing in a bad place;
there should be a more compreensive aproach to these situations so we can map this for safety first; then, we should take this stuff to city hall and press for more permanent proper solutions, like new crossroads and better safety measures!!!
as to sidewalks, it’s a bad situation; there are not as many as i believe there should be (this gets really bad as you get farther from the city center).
so many of the newer roads and rotundas dont even have a proper sidewalk, like whaaat;
i do this out of sheer worry bcs i know how hard it is to navigate the city while not knowing which side of the road you should be on to be able to actually get where you wanna go, bcs sidewalks collapse onto the road or suddenly dissappear into nowhere. (“wheres the crosswalk?”) so this feels important specially to point people towards the safest marked crossing and so they can check which sidewalk is in better state etc.
also i really like informal paths, and pedestrian exclusive paths like alleyways or roadside paths… i’ve added some of those to guimaraes already also;
one interesting case i found is this (rare in Braga) alley, which is closed off by a fence way/1463261788; - which is kind of a similar situation to this in guimaraes way/1463370151 ; in both cases they are exclusively pedestrian paths, which do exist, where built up, in the case of guimaraes have even public lighting equipment and stuff but they are closed off to the public (god knows why)= so i added them out of curiosity for osm urban dwellers; i tried to keep them clearly tagged as closed or having no entry or exit, but they do exist so i believe its ok to have them mapped, even if they are not allowed access for some reason
mapping for accessibility is a goal, but a bit complex; i havent mapped curbs to most of my crosswalk interventions yet, bcs sometimes its hard to know whats their state;
a thing i like are wayside shrines, i’m starting to map them, i’ve added 3 or 4 so far;
.jpg)































 in Braga, Portugal | ©
in Braga, Portugal | ©  ►
►
 ►
►